From_Catalog Aws Glue
From_Catalog Aws Glue - Api reference for the aws glue data catalog. We’re excited to announce the general availability of hive metastore (hms) and aws glue federation in unity catalog! Populate the aws glue data catalog with metadata tables from data stores. It provides a unified interface to store and query information about data. Today, we announce support for aws glue data catalog views with aws glue 5.0 for apache spark jobs. The catalog object represents a logical grouping of databases in the aws glue data catalog or a federated source. With aws glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog. Use this tutorial to create your first aws glue data catalog, which uses an amazon s3 bucket as your data source. Glue catalog is only a aws hive implementation itself. The amazon glue data catalog is your persistent technical metadata store. Simplifies setting up, securing, and managing the data lake. Glue catalog is only a aws hive implementation itself. It allows users to discover, transform, and load data from various sources into data lakes, databases, or data warehouses, making it easy to analyze large datasets. In this tutorial, we will use aws glue to demonstrate a common etl (extract, transform, load) task: The catalog object represents a logical grouping of databases in the aws glue data catalog or a federated source. Creates a new catalog integration in the account or replaces an existing catalog integration for apache iceberg™ tables that use aws glue as the catalog. Automatically discovers, catalogs, and organizes data across s3. It provides a unified interface to store and query information about data. You create a glue catalog defining a schema, a type of reader, and mappings if required, and then this becomes. Populate the aws glue data catalog with metadata tables from data stores. You create a glue catalog defining a schema, a type of reader, and mappings if required, and then this becomes. Converting csv files stored in an s3 bucket into parquet format. It is a managed service that you can use to store, annotate, and share metadata in the amazon cloud. Populate the aws glue data catalog with metadata tables from. It allows users to discover, transform, and load data from various sources into data lakes, databases, or data warehouses, making it easy to analyze large datasets. You can visually create, run, and monitor extract,. Populate the aws glue data catalog with metadata tables from data stores. It is a managed service that you can use to store, annotate, and share. It allows users to discover, transform, and load data from various sources into data lakes, databases, or data warehouses, making it easy to analyze large datasets. Converting csv files stored in an s3 bucket into parquet format. You can visually create, run, and monitor extract,. Automatically discovers, catalogs, and organizes data across s3. Simplifies setting up, securing, and managing the. We’re excited to announce the general availability of hive metastore (hms) and aws glue federation in unity catalog! The amazon glue data catalog is your persistent technical metadata store. The aws glue data catalog is a centralized metadata repository for all your data assets across various data sources. It allows users to discover, transform, and load data from various sources. Aws glue data catalog views with aws glue 5.0 allows. The catalog objects api describes the data types and api related to working with catalogs in aws glue. The catalog object represents a logical grouping of databases in the aws glue data catalog or a federated source. Automatically discovers, catalogs, and organizes data across s3. In this tutorial, we will. Aws glue data catalog views with aws glue 5.0 allows. Api reference for the aws glue data catalog. It provides a unified interface to store and query information about data. You create a glue catalog defining a schema, a type of reader, and mappings if required, and then this becomes. The amazon glue data catalog is your persistent technical metadata. Automatically discovers, catalogs, and organizes data across s3. The catalog object represents a logical grouping of databases in the aws glue data catalog or a federated source. It provides a unified interface to store and query information about data. Use this tutorial to create your first aws glue data catalog, which uses an amazon s3 bucket as your data source.. You can visually create, run, and monitor extract,. We’re excited to announce the general availability of hive metastore (hms) and aws glue federation in unity catalog! In this tutorial, we will use aws glue to demonstrate a common etl (extract, transform, load) task: With aws glue, you can discover and connect to more than 70 diverse data sources and manage. Converting csv files stored in an s3 bucket into parquet format. In this tutorial, we will use aws glue to demonstrate a common etl (extract, transform, load) task: It allows users to discover, transform, and load data from various sources into data lakes, databases, or data warehouses, making it easy to analyze large datasets. Learn the features of aws glue,. Glue catalog is only a aws hive implementation itself. It is a managed service that you can use to store, annotate, and share metadata in the amazon cloud. It provides a unified interface to store and query information about data. The amazon glue data catalog is your persistent technical metadata store. The catalog object represents a logical grouping of databases. Populate the aws glue data catalog with metadata tables from data stores. You create a glue catalog defining a schema, a type of reader, and mappings if required, and then this becomes. It is a managed service that you can use to store, annotate, and share metadata in the amazon cloud. We’re excited to announce the general availability of hive metastore (hms) and aws glue federation in unity catalog! Use this tutorial to create your first aws glue data catalog, which uses an amazon s3 bucket as your data source. It provides a unified interface to store and query information about data. Simplifies setting up, securing, and managing the data lake. In this tutorial, we will use aws glue to demonstrate a common etl (extract, transform, load) task: Today, we announce support for aws glue data catalog views with aws glue 5.0 for apache spark jobs. It allows users to discover, transform, and load data from various sources into data lakes, databases, or data warehouses, making it easy to analyze large datasets. The catalog object represents a logical grouping of databases in the aws glue data catalog or a federated source. The catalog objects api describes the data types and api related to working with catalogs in aws glue. Creates a new catalog integration in the account or replaces an existing catalog integration for apache iceberg™ tables that use aws glue as the catalog. With aws glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog. Api reference for the aws glue data catalog. Learn the features of aws glue, a serverless etl service that crawls your data, builds a data catalog, and performs data preparation, data transformation, and data ingestion to make your.
Getting started with AWS Glue Data Quality from the AWS Glue Data

Simplify data discovery for business users by adding data descriptions
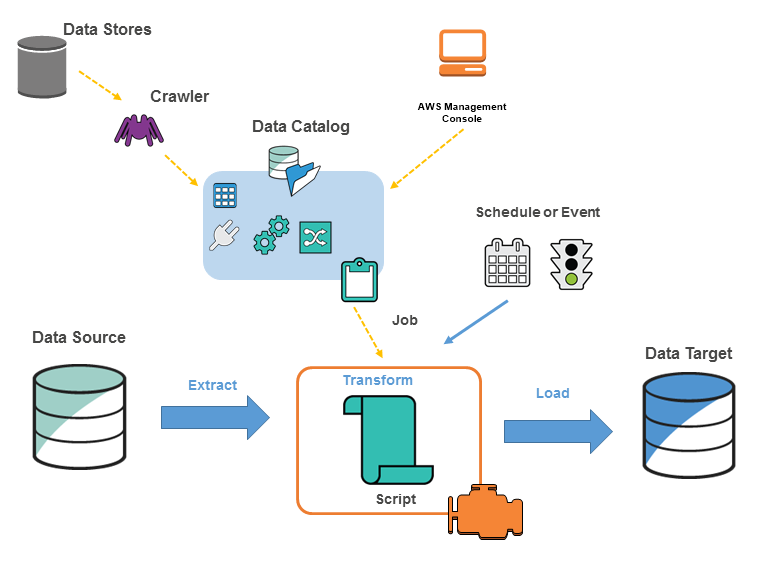
AWS Glue Concepts AWS Glue

Build operational metrics for your enterprise AWS Glue Data Catalog at

Aws Glue Examples

AWS Glue Data Catalog as the centralized metastore for Athena & PySpark

What is Amazon AWS Glue?

Populating the AWS Glue Data Catalog AWS Glue
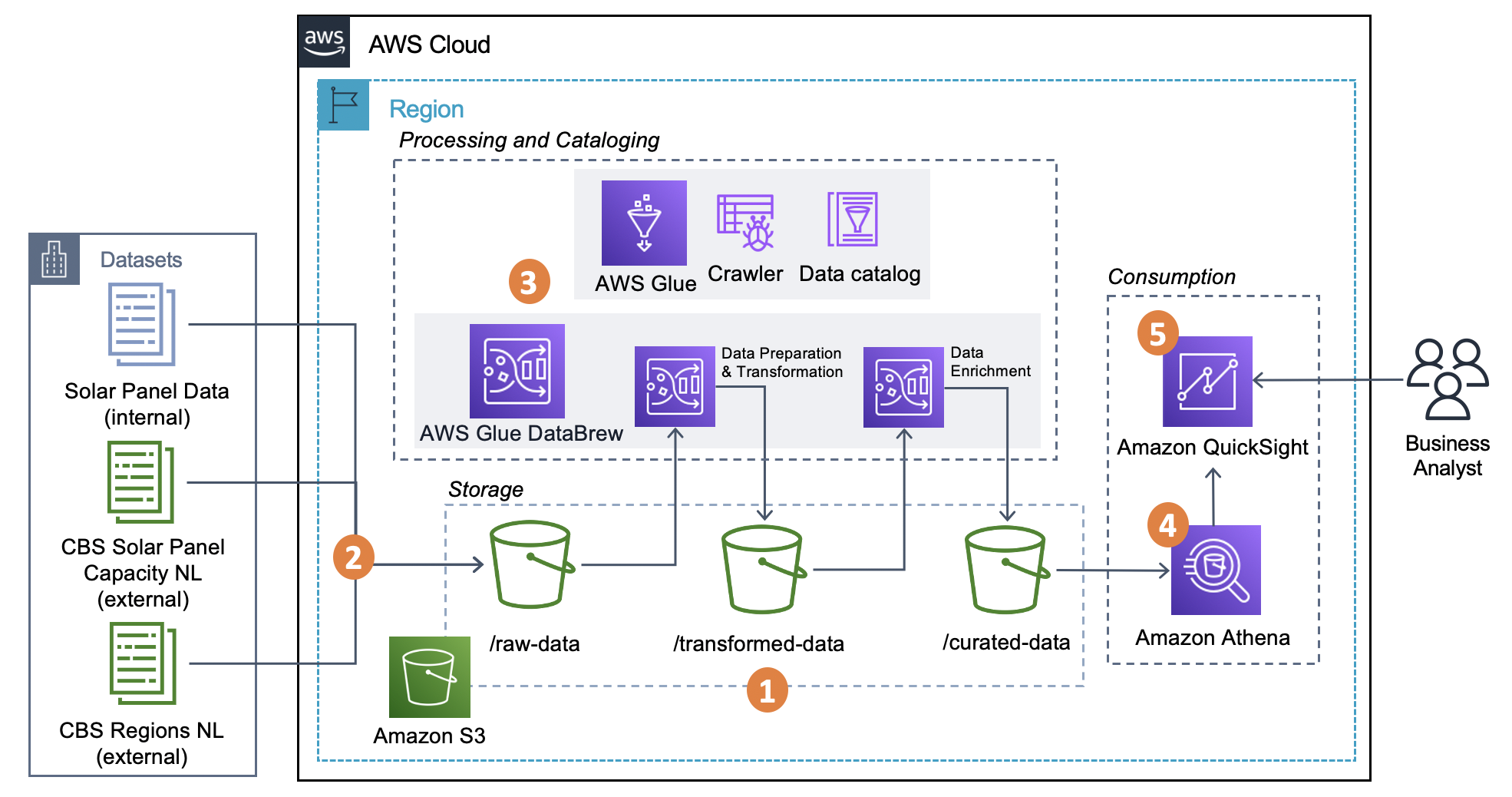
Enrich datasets for descriptive analytics with AWS Glue DataBrew AWS

Access Amazon S3 data managed by AWS Glue Data Catalog from Amazon
Converting Csv Files Stored In An S3 Bucket Into Parquet Format.
This New Capability Enables Unity Catalog To.
Glue Catalog Is Only A Aws Hive Implementation Itself.
Aws Glue Data Catalog Views With Aws Glue 5.0 Allows.
Related Post: